

OpenAI presenta GPT-4.5
Estamos lanzando una vista previa de investigación de GPT‑4.5, nuestro modelo más grande y mejor para chat hasta el momento. GPT‑4.5 es un paso adelante en la ampliación del entrenamiento previo y posterior. Al ampliar el aprendizaje no supervisado, GPT‑4.5 mejora su capacidad para reconocer patrones, establecer conexiones y generar conocimientos creativos sin razonamiento.
Las primeras pruebas muestran que interactuar con GPT‑4.5 resulta más natural. Su base de conocimiento más amplia, su capacidad mejorada para seguir las intenciones del usuario y su mayor “coeficiente emocional” lo hacen útil para tareas como mejorar la escritura, la programación y la resolución de problemas prácticos. También esperamos que alucine menos.
Estamos compartiendo GPT‑4.5 como una vista previa de la investigación para comprender mejor sus fortalezas y limitaciones. Aún estamos explorando sus capacidades y estamos ansiosos por ver cómo la gente la usa de maneras que quizás no esperábamos.
Ampliación del aprendizaje no supervisado
Desarrollamos capacidades de IA escalando dos paradigmas complementarios: aprendizaje no supervisado y razonamiento. Estos representan dos ejes de inteligencia.
- El razonamiento escalable enseña a los modelos a pensar y producir una cadena de pensamientos antes de responder, lo que les permite abordar problemas complejos de STEM o lógica. Modelos como OpenAI o1 y OpenAI o3‑mini promueven este paradigma.
- El aprendizaje no supervisado, por otro lado, aumenta la precisión y la intuición del modelo mundial.
GPT‑4.5 es un ejemplo de cómo escalar el aprendizaje no supervisado mediante la ampliación de los recursos informáticos y de datos, junto con innovaciones en la arquitectura y la optimización. El resultado es un modelo que posee un conocimiento más amplio y una comprensión más profunda del mundo, lo que conduce a una reducción de las alucinaciones y a una mayor fiabilidad en una amplia gama de temas.
Escalando el paradigma GPT
GPT-4.5 (2025)
¿Cuál fue el primer idioma?
No sabemos exactamente cuál fue el primer idioma, y los científicos creen que probablemente nunca lo sabremos con seguridad porque las lenguas habladas aparecieron mucho antes de que existieran registros escritos.
Esto es lo que sabemos:
- No existe una única «primera lengua»: es probable que las lenguas se desarrollaran gradualmente en diferentes grupos de humanos aproximadamente al mismo tiempo, hace decenas o incluso cientos de miles de años.
- Origen en África: La mayoría de los científicos coinciden en que el lenguaje hablado probablemente surgió por primera vez entre los humanos en África, quizás hace más de 100.000 años.
- Protolenguajes: En lugar de un único idioma, es probable que los seres humanos comenzaran con una comunicación sencilla que evolucionó hacia lenguajes más complejos. Las primeras formas de lenguaje probablemente incluían gestos, sonidos y señales para expresar ideas y emociones básicas.
- Perdido para la historia: debido a que el habla no deja registro fósil directo y la escritura surgió hace relativamente poco tiempo (hace unos 5.000 años), no tenemos forma de saber exactamente cómo sonaban los primeros idiomas.
Hoy en día, los lingüistas estudian los idiomas existentes para comprender cómo evolucionaron a lo largo de miles de años, pero la identidad exacta de la primera lengua de la humanidad sigue siendo (y probablemente seguirá siendo siempre) un misterio.
Un conocimiento más profundo del mundo
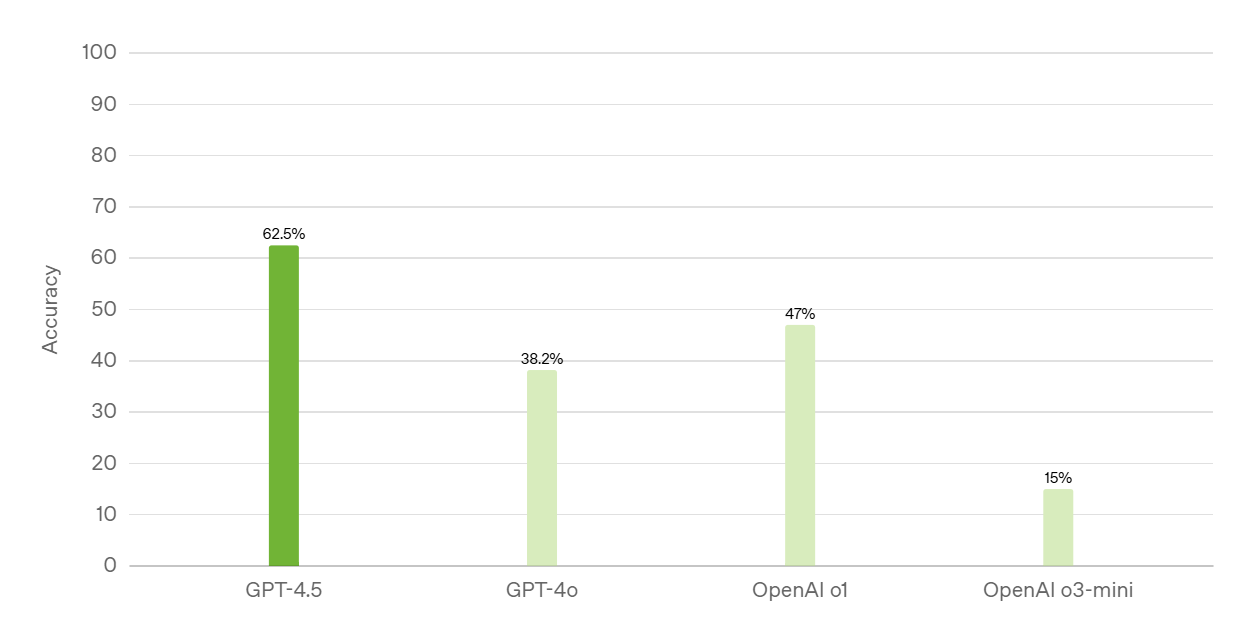
Precisión de SimpleQA (cuanto mayor, mejor)
Tasa de alucinaciones de SimpleQA (cuanto menor, mejor)
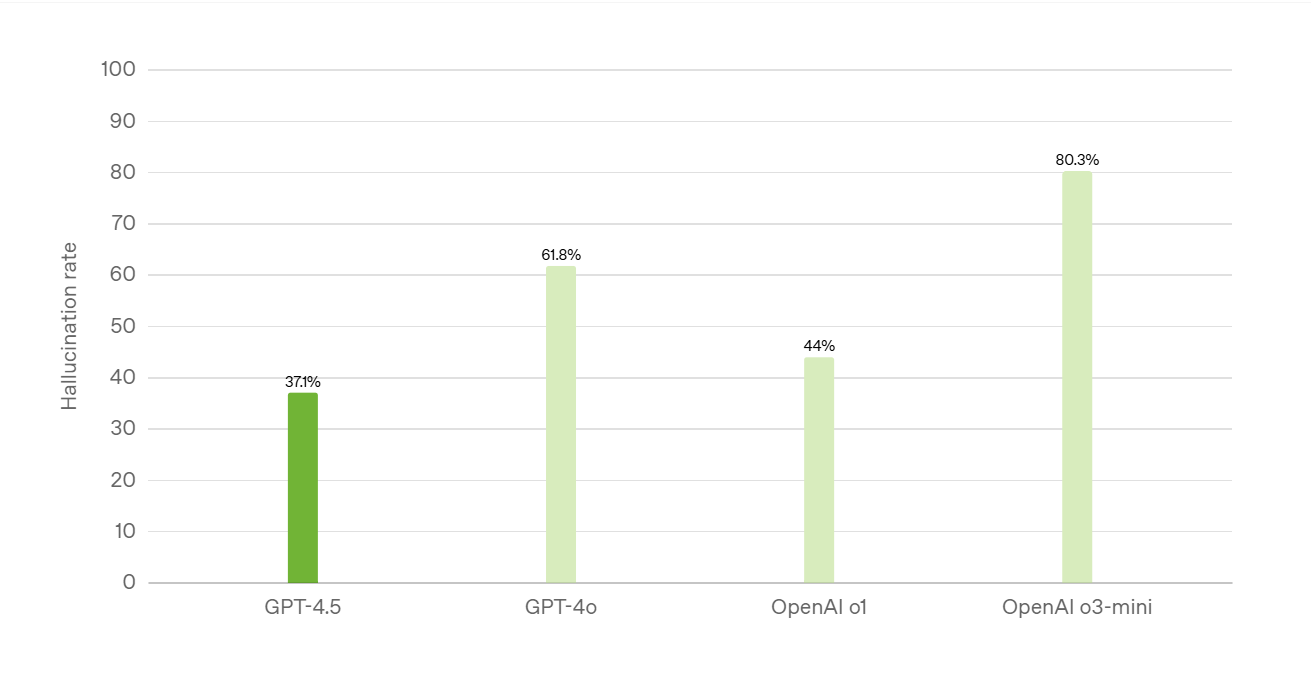
SimpleQA mide la factibilidad del LLM (modelo de lenguaje grande) en preguntas de conocimiento sencillas pero desafiantes.
Formación para la colaboración humana
A medida que escalamos nuestros modelos y estos resuelven problemas más complejos, se vuelve cada vez más importante enseñarles una mayor comprensión de las necesidades y las intenciones humanas. Para GPT‑4.5, desarrollamos nuevas técnicas escalables que permiten entrenar modelos más grandes y más potentes con datos derivados de modelos más pequeños. Estas técnicas mejoran la capacidad de dirección de GPT‑4.5, la comprensión de los matices y la conversación natural.
Evaluaciones comparativas con probadores humanos
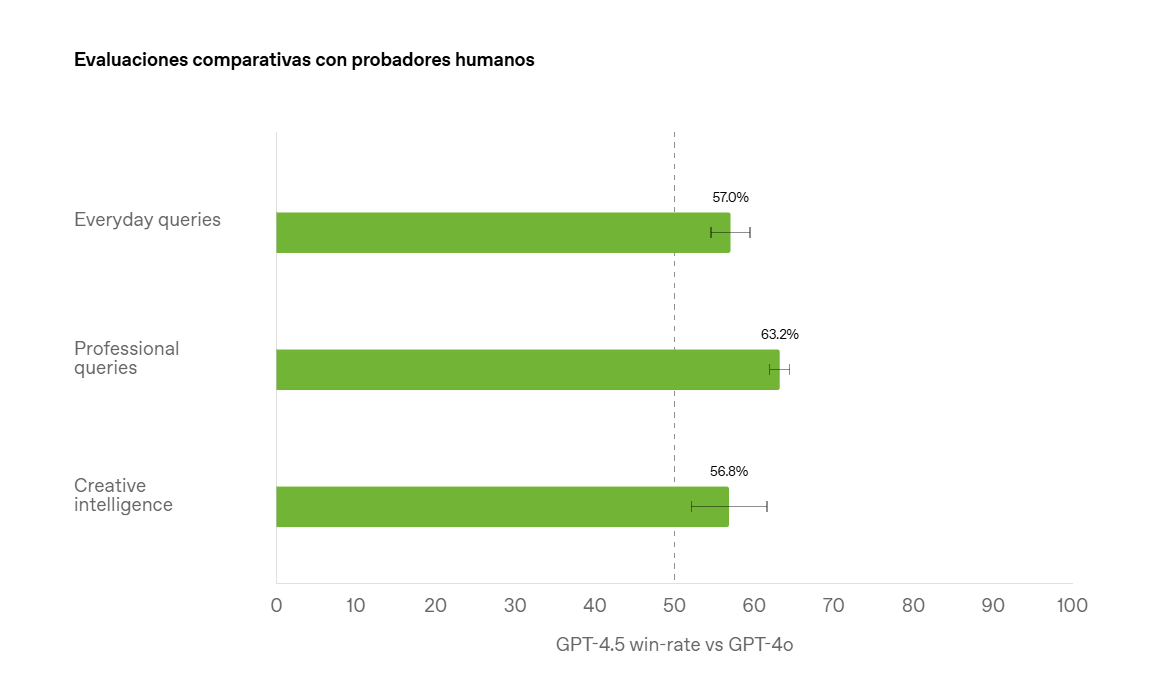
La preferencia humana mide el porcentaje de consultas en las que los evaluadores prefirieron GPT‑4.5 sobre GPT‑4o.
La combinación de una comprensión profunda del mundo con una colaboración mejorada da como resultado un modelo que integra las ideas de forma natural en conversaciones cálidas e intuitivas que están más en sintonía con la colaboración humana. GPT‑4.5 comprende mejor lo que los humanos quieren decir e interpreta las señales sutiles o las expectativas implícitas con mayor matiz y “emoción emocional”. GPT‑4.5 también muestra una mayor intuición estética y creatividad. Se destaca por ayudar con la escritura y el diseño.
Un razonamiento más fuerte en el horizonte
GPT‑4.5 no piensa antes de responder, lo que hace que sus puntos fuertes sean particularmente diferentes de los modelos de razonamiento como OpenAI o1. En comparación con OpenAI o1 y OpenAI o3‑mini, GPT‑4.5 es un modelo de propósito más general e intrínsecamente más inteligente. Creemos que el razonamiento será una capacidad central de los modelos futuros y que los dos enfoques de escalado (entrenamiento previo y razonamiento) se complementarán entre sí. A medida que los modelos como GPT‑4.5 se vuelvan más inteligentes y tengan más conocimientos a través del entrenamiento previo, servirán como una base aún más sólida para el razonamiento y los agentes que utilizan herramientas.
Seguridad
Cada aumento en las capacidades del modelo es también una oportunidad para hacerlos más seguros. GPT‑4.5 fue entrenado con nuevas técnicas de supervisión que se combinan con métodos tradicionales de ajuste fino supervisado (SFT) y aprendizaje de refuerzo a partir de retroalimentación humana (RLHF) como los utilizados para GPT‑4o. Esperamos que este trabajo sirva como base para alinear modelos futuros aún más capaces.
Para poner a prueba nuestras mejoras, realizamos una serie de pruebas de seguridad antes de la implementación, de acuerdo con nuestro Marco de preparación. Descubrimos que la ampliación del paradigma GPT contribuyó a mejorar la capacidad en todas nuestras evaluaciones. Publicamos los resultados detallados de estas evaluaciones en la tarjeta del sistema adjunta.
Cómo utilizar GPT-4.5 en ChatGPT
A partir de hoy, los usuarios de ChatGPT Pro podrán seleccionar GPT‑4.5 en el selector de modelos en la web, dispositivos móviles y computadoras de escritorio. Comenzaremos a implementar la versión para los usuarios de Plus y Team la próxima semana, y luego para los usuarios de Enterprise y Edu la semana siguiente.
GPT‑4.5 tiene acceso a la información más actualizada con búsqueda, admite la carga de archivos e imágenes y puede usar Canvas para trabajar en la escritura y el código. Sin embargo, GPT‑4.5 actualmente no admite funciones multimodales como el modo de voz, el video y la pantalla compartida en ChatGPT. En el futuro, trabajaremos para simplificar la experiencia del usuario para que la IA «simplemente funcione» para usted.
Cómo utilizar GPT-4.5 en la API
También estamos ofreciendo una vista previa de GPT‑4.5 en la API de finalización de chat, la API de asistentes y la API de lotes para desarrolladores en todos los niveles de uso pago. El modelo admite funciones clave como llamadas de funciones, salidas estructuradas, transmisión y mensajes del sistema. También admite capacidades de visión a través de entradas de imágenes.
Según las primeras pruebas, los desarrolladores pueden encontrar que GPT‑4.5 es particularmente útil para aplicaciones que se benefician de su mayor inteligencia emocional y creatividad, como la ayuda para la redacción, la comunicación, el aprendizaje, el coaching y la generación de ideas. También muestra sólidas capacidades en la planificación y ejecución de agentes, incluidos flujos de trabajo de codificación de varios pasos y automatización de tareas complejas.
GPT‑4.5 es un modelo muy grande y que requiere un uso intensivo de recursos informáticos, lo que lo hace más costoso que GPT‑4o y no lo reemplaza. Por este motivo, estamos evaluando si continuar brindándolo en la API a largo plazo mientras equilibramos el soporte de las capacidades actuales con la creación de modelos futuros. Esperamos aprender más sobre sus fortalezas, capacidades y posibles aplicaciones en entornos del mundo real. Si GPT‑4.5 ofrece un valor único para su caso de uso, sus comentarios. Desempeñará un papel importante a la hora de orientar nuestra decisión.
Conclusión
Cada nuevo orden de magnitud de computación trae consigo nuevas capacidades. GPT‑4.5 es un modelo que se encuentra en la frontera de lo que es posible en el aprendizaje no supervisado. Seguimos sorprendiéndonos con la creatividad de la comunidad a la hora de descubrir nuevas capacidades y casos de uso inesperados. Con GPT‑4.5, lo invitamos a explorar la frontera del aprendizaje no supervisado y descubrir nuevas capacidades con nosotros.
Apéndice
A continuación, presentamos los resultados de GPT‑4.5 en los puntos de referencia académicos estándar para ilustrar su desempeño actual en tareas tradicionalmente asociadas con el razonamiento. Incluso al ampliar únicamente el aprendizaje no supervisado, GPT‑4.5 muestra mejoras significativas en comparación con modelos anteriores como GPT‑4o. Aun así, esperamos obtener una imagen más completa de las capacidades de GPT‑4.5 a través de esta versión, porque reconocemos que los puntos de referencia académicos no siempre reflejan la utilidad en el mundo real.
Puntuaciones de evaluación del modelo
| GPT‑4.5 | GPT‑4o | OpenAI o3‑mini (alto) | |
| GPQA (ciencia) | 71,4% | 53,6% | 79,7% |
| AIME ’24 (matemáticas) | 36,7% | 9,3% | 87,3% |
| MMMLU (multilingüe) | 85,1% | 81,5% | 81,1% |
| MMMU (multimodal) | 74,4% | 69,1% | – |
| SWE-Lancer Diamond (codificación)* | 32,6% $186,125 | 23,3% $138,750 | 10,8% $89,625 |
| SWE-Bench verificado (codificación)* | 38,0% | 30,7% | 61,0% |
*Los números mostrados representan el mejor rendimiento interno.



